
You may have noticed that the Google Search Console gives you a link to a new version. Well! This new version is great for at least one thing: it actually tells you about your excluded pages, not only a link to them but the reason why they decided to exclude said pages from their index. This is super practical in order to be able to fix your pages quickly. Before there was no such information about why some pages would not make it and it was 100% guesswork to apply fixes. Since you did not even know which page, on a large website, there was close to no way to know what was happening. Period.
The picture at the top shows you the four items that Google now offers: Errors, Warnings, Valid, and Excluded. With the old console, they only offered the list of Errors, which was better than nothing, although it really only had the following few errors in that report:
- 403 Forbidden
- 404 Not Found
- 500 Server Error
Not much to go on.
How to Fix Errors
This new console gives you a list of errors as before.
This list includes the same pages as in the old console. For example, if you delete a page and do not add a 301 redirect to a new location for that page, Google will report it as an error.
If you really can’t have a 301 for that page, I suggest you look into your setup and return a 410 Gone error instead. The 404 will stick around forever. A 410 error gets removed for about a month or two.
With Apache, you can add this instruction in your <VirtualHost> or your .htaccess definition:
Redirect gone /the-path/to-the-page/that-was-deleted
The Redirect instruction is pretty much always available, but make sure that your changes work as expected by going to that old page and making sure you get the 410 Gone error as expected, and not on other pages.
If you modify a file in your /etc/apache2 settings, remember you have to reload the files. On a modern Debian or Ubuntu system, you do this:
sudo systemctl reload apache2
You may just reboot your system if you’re not too sure how to do it otherwise.
About errors, at times your server may just not answer Google. At least that’s what I think happens when you get the error message:
Submitted URL has crawl issue
If these errors persist for a long time or new one pop up all the time, then you probably have a connection problem with your website. I have that error pop up on a site that I host on a home server and my connection goes down once in a while. Also at times I reboot the computer and that’s a slow one… So that’s why I suspect this issue is likely to be connections issues rather than crawl issues per se. Also, in my case, the pages referenced work just fine when I’m on my computer and check them.
301 Redirect SEO Penalty
You may have read that using a 301 Redirect can generate an SEO Penalty. This is correct. A direct link from a good website to your website is going to be like gold.
A link on your someone’s website that hits one of your 301 is going to be pretty good, it could be better if the link could be updated on their website to the new destination, though.
A link that goes through a third party system such as bit.ly, addthis, etc. includes a 301 as well. Those are not too bad, but because they are from a third party website, they have yet less weight than your own 301 Redirects.
Also, links that first go through a third party system as mentioned in the previous paragraph, and then hit your website and again do a 301 Redirect, are going to be more penalized than links that have a single 301 Redirect. For sure, your own website (what you have full control over) should not do a 301 to another 301. The Broken Link Checker plugin can be used to help you find such double redirects on your website. The penalty for multiple 301 in a row increases dramatically, probably at a logarithmic speed, and is limited to an undisclosed number (i.e. a 301 to a 301 to a 301 … too many times, and GoogleBot stops en route and any juice left is lost.)
However, in all cases, getting a little bit of Juice is very much more positive than getting Juice to a 404 or a 410, because that one is for sure lost.
How to Fix Warnings
Unfortunately, at this point, I have not received warnings so I’m not totally sure what they are in the New Google Search Console.
These are likely temporary errors such as a 500 Server Error. In other words, Google lets you know that whenever their spider tried to reach your server it encountered some problem. However, there is nothing to fix on your website per se, only your server needs to be back on its feet.
If you get some warnings, please post a comment about them. I would be grateful if you did.
Valid Pages
That page includes an entry of valid pages. These are all the pages that are included in the Google Index and are considered valid and kicking. These are the pages your visitors will eventually find you in their search.
Note that this Google Interface limits the number of pages that they show to 1,000. If your website has more than 1,000 pages, you will only see that many on this list. Don’t be alarmed, it’s normal. The number shown at the top is the total number of pages on that list. In any event, it’s probably not very useful to find a certain page in this list. The most important part is to not find it in the other lists (Errors or Excluded especially.)
How to Fix Excluded Pages
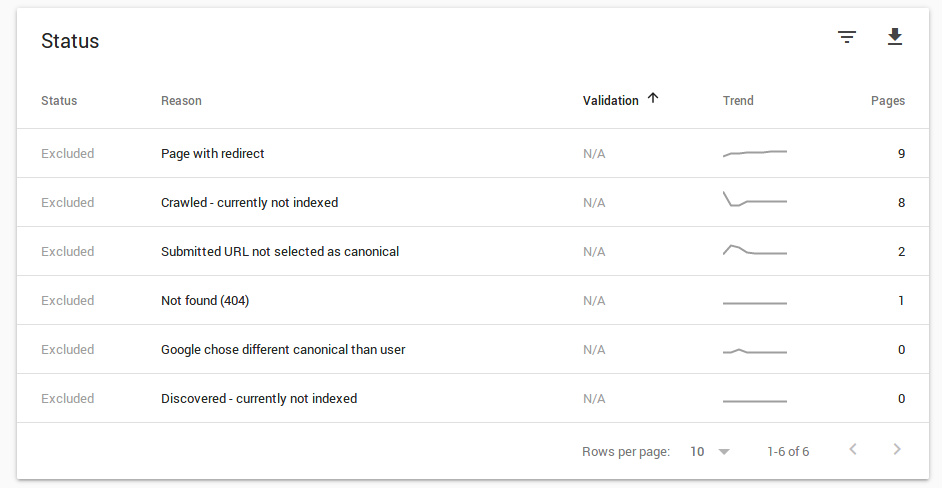
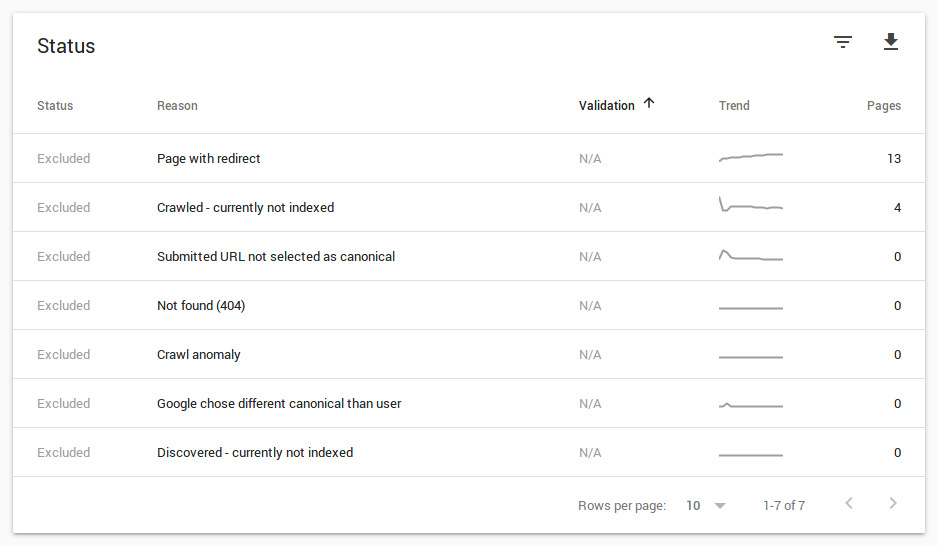
The list of pages under the Excluded Pages is the most important one, I think. Errors are very important, but in most cases, these are easy and quick to fix. The excluded pages can be harder to fix as they are quite diverse.
Whenever you click on that one button at the top, you get a list of reasons for exclusion below the graph. Note that our list may be shorter or longer depending on which errors you had. If you never had a certain exclusion error, then you won’t get an entry at all for it. That’s normal and probably a good thing. Once an error occurred to you, it looks like it sticks around, though, even when the counter drops back to zero.
In the following, I describe various errors I got which got some of my pages excluded from the index and explain why it happens and how to fix the problem.
Excluded Page: Page with Redirect
The Google Search Console now tells you of all the pages with a Redirect on them (well, up to 1,000 of them at least).
These are pages you had earlier and change the URL of, or pages you deleted and are now using a 301 to a new location on your website (or even on another website.)
In most cases, there is nothing to do about those. It is totally normal to have redirects and there is really no reasons for such pages to be part of the Google Index. Therefore, you should leave these alone.
Yet, there is one case where you could do something about your 301 warnings. If you wanted to write a page which better corresponds to one of those old pages, you could decide to reuse that URL for your new page. This is perfectly legal. I’ve done that before, but never tried to track how the new page would do in search engines. From what I’ve read, though, it’s not a bad idea to reuse old URLs so you should be just fine doing that too.
Excluded Page: Crawled – Currently Not Indexed
This one lets you know of pages that Google knows about, but that it decided not to include in their index.
I have a theory as to why that could happen, but so far I have no real proof. All my pages are decidedly unique (I wrote them all from scratch) but still, I think that Google views these few pages (I have 4 on that list) as duplicates from other websites out there. It could be because the subject is close to another page on the Internet.
In my case, I have these four pages on that list:
- All Your Amazon Affiliate Links Must Be Public and Other Restrictions
- Creating My Niche Website, Step by Step
- HTML and CSS, The Basics so You Become Dangerous
- First Step in Creating a Niche Website
To me it looks like all four pages are rather distinct:
- A page about Internet Affiliate on Amazon and what to be cautious about
- A short page about niche website (really a list of links to various other pages)
- A technical page about HTML and CSS, the basic technology used to create web pages
- The page explaining how to start with creating your Niche Website
So really it does not make much sense to me if it were really a duplication problem. I really created all those pages myself by hand…
Anyway, I’ll update this section if I am to find out more about this problem. I noticed that new pages often get in there for a little while, but they quickly get indexed (like within one month.) These 4, though, have been on that list like forever!
Excluded Pages: Alternate page with proper canonical tag
This is more of a service to you than a warning, although it can be useful to see alternative URLs for pages. In some cases you may want to remove those alternatives.
The list of URLs shows valid pages which have a valid canonical different from the URL shown, but is considered valid/better by Google. In other words, Google is telling you that everything is in order.
In my case, this happens on one of my sites where GoogleBot decided to add all sorts of Query Strings at the end of the URL. For example the transformed:
https://www.example.com/this-page-here
Into a URL such as:
https://www.example.com/this-page-here?test=123
and since my CMS ignores the “test=123” part, the page appears the same either way. However, I avoid the “Duplicate” error because I have a canonical properly defined and on both pages shown above, the both reference the first one.
Excluded Pages: Submitted URL not Selected as Canonical
This one is different from the other Canonical error in that the “Submitted URL” refers to a URL that you specified in your sitemap.xml file.
For efficiency, the sitemap.xml file is expected to only include canonical URLs.
The sitemap.xml plugin I used with WordPress would include the /home page which WordPress generates by default. Unfortunately, that default page really is the homepage and thus it’s path is just /. This is viewed as a mismatch and generated this error.
I fixed the problem by making sure /home would not be included in the sitemap.xml file and by redirecting /home to / so GoogleBot sees a 301 on that one and not a duplicated page.
Excluded Pages: Excluded by ‘noindex’ tag
It is possible to exclude a page from search engine indexes by marking them with the ‘noindex’ attribute. There are mainly two ways to add that attribute.
One, set it up in HTML through a meta tag:
<meta names="robots" content="noindex"/>
The other way is to tweak your HTTP server (no everyone can do that one!) and add the “noindex” attribute there:
X-Robots-Tag: noindex
This is very similar to having a block of the page by your robots.txt file.
There are two potential problems when you block a page in this way: you must make sure that it’s not included in your sitemap.xml (since it’s not to be indexed it should not appear in the list of pages you’d like to see indexed!) and links to that page should bear the rel=”nofollow” attribute or you will get another error (see Crawl Anomaly).
Excluded Pages: Soft 404
At times you have to wonder about the terminology that some people come up with. Soft 404… Would that means there are other types of 404 too? Like a hard one, a long one, a skinny one… Sorry I diverge here.
The Soft 404 is a page that could not be accessed by did not return an actual 404 error. Google Index keeps all the URLs it ever finds on your website and checks them over and over again. You can have a 404, 410, etc. and yet Google will continue to test those pages. After a while it stops tell you about the error (probably because those are removed from the searchable index,) but it doesn’t stop checking those pages, in case they were to re-appear.
In my case, I have pages that it probably couldn’t access even though they still exist (and work just fine when I test them) and I have some 410 Gone pages in this list. If you get many such errors for pages that seem to otherwise work for you, you may have a connectivity problem.
Excluded Pages: Not Found (404)
Since by default you have the Error tab selected in the graph above, you are not unlikely to see an entry that says Not Found (404).
This entry is about errors, but obviously, Google is not going to index pages that return a 404 error. There would really be no point in sending users to such pages (even if they have some fun graphics).
The point here is to let you know that you have some missing pages. It could be a temporary problem such as a database that’s not accessible or a software that is currently offline. In such cases, the errors should get resolved once your server is back on track.
Other 404 Not Found errors should be fixed by using either
- A 301 Redirect to a new location that makes sense.
Note that some people don’t bother and redirect all to their homepage, this is not always a good choice, though. The homepage is not always a match for what that old page was about. To the minimum, try to find a match and if you really don’t see one in your existing pages, then send these users to the homepage.
- The other fix is to use a 410 Gone error. I show how you can do that above with Apache. The 410 error tells Google that the page is really not there anymore. Whereas a 404 will generally stick around for years. That being said, a 404 can be kept as such as long as you’d like. It won’t hurt your website SEO unless you have many of them all at once (when you delete a large section of your website.)
Excluded Pages: Crawl Anomaly
Whenever the GoogleBot computers crawl your website, they may detect problems that Google reports in this list.
A common problem would be a page that has a redirect loop. So a redirect that sends the user (and thus GoogleBot) to itself. Attempting to reload the page over and over again would not result in anything. This is a Crawl Anomaly and the redirect loop is probably one of the main ones you’ll ever encounter.
The other ones I get in this list are pages that are 410 Gone. These will automatically disappear with time, though and there is nothing to worry about in this case.
Excluded Pages: Duplicate page without canonical tag
Now this error is probably one of the worst. You don’t want to have duplicated data errors. I strongly suggest that you look at fixing these errors as quickly as you can.
In some cases, these are due to having a website that responds with the same content when you add one or more query string that it ignores. In all cases you can fix these errors with a canonical, although in case of the query string, you could also do a 301 to redirect the user to the canonical URL. This should always work too, although some CMS do handle some query string transparently (at least as far as the end user is concerned, the page will look identical either way,) so doing a redirect may not always be possible.
Excluded Pages: Google Chose Different Canonical Than User
As the error says, GoogleBot read a page with a canonical path which did not match the page.
I use the Minify HTML WordPress plugin in order to compress the HTML, JavaScript, and CSS code before sending it to Apache for further compression (with the z library) and sending that as the response to my visitors.
A beautified HTML code snippet will look like this:
<section class="main"> <h2>This is a neatly formatted HTML code snippet</h2> <p>It has newlines and indentation to make it easy to read.</p> </section>
The fact is that the nice formatting can be removed and it will have no impact on the resulting page (unless your browser is broken, but now a day, that’s not common!)
The example above ends up on a single long line of HTML code:
<section class="main"><h2>This is a neatly formatted HTML code snippet</h2><p>It has newlines and indentation to make it easy to read.</p></section>
This may not look like much to you, but such minification can actually save you 10% to 20% which when you receive 1 million hits per month is a lot of bandwidth saved.
The Minify HTML plugin will also go through the code and remove any reference to the same domain. As I explain about Internal Links, it is possible to shorten them by removing the protocol and domain name part. Only the Minify plugin does it against the canonical meta tag as well. So it transforms:
<link rel="canonical"
url="https://www.internetaffiliate.com/my-page"/>Into:
<link rel="canonical"
url="/my-page"/>Which in itself is a great minification, only it’s completely invalid. I entered a bug report for it and the author said that since you can turn off that feature, it was not a bug. It’s just that this specific feature is therefore totally useless, which is sad because many other links would benefit from that minification.
Oh well…
So in my case, the reason I had that error entry was that the Minify HTML WordPress plugin and I turned on that feature to minify URLs. Your case may be different. In any event, you need to find out why your canonical would be URL A on page B. The URL of the page and its canonical need to match one to one.
If the canonical link says “https://www.example.com/my-page” then going to that very page must present a canonical of “https://www.example.com/my-page”.
Another page, say “https://www.example.com/my-page-duplicate” may have the canonical of “https://www.example.com/my-page” if indeed it is a duplicate and going to “https://www.example.com/my-page” shows the right canonical.
Excluded Pages: Discovered – Not Currently Indexed
This one is simple enough to understand. Your sitemap.xml may not include certain pages on your website. Especially, Content Management Systems (CMS) are notorious for adding your pages to the sitemap.xml, but not meta-pages; pages created automatically such as lists of other pages or automatic pages that reference things such as the date and show the corresponding moon. Such pages being fully dynamic, they are often not included in the sitemap.xml.
The fact that such pages are excluded just means that they were not yet fully analyzed for inclusion. There is nothing for you to do. In most cases, these will disappear from this list over a short period of time (i.e. about one month.)
If your website does not include a sitemap.xml that you submitted to your Google Search Console (and that’s fine if you do so), then this entry will include your new pages as they are found by Google.
Note that GoogleBot does not always re-read the sitemap.xml file before checking other pages on your website such as your homepage. This means you may end up with a new entry under this label even though your page is indeed included in your sitemap.xml. So don’t be alarmed if you see pages appearing here. It’s common.
This list mainly gives you the ability to see how long it takes for your pages to get indexed.
Excluded Pages: Blocked by robots.txt
Your robots.txt may be blocking some pages (it’s very likely if you have a robots.txt file.)
This error is shown to pages that are linked without a rel=”nofollow” attribute. Links to pages that you ask a robot not to index should be marked that way. More or less a link to a page without the rel=”nofollow” is a way to tell a robot: “Please consider indexing that destination page.” This is also why Google doesn’t like links to a sales page without a nofollow attribute.
Valid: Submitted and Indexed
When you select the Valid tab, you see this entry. This shows you 1,000 of your valid pages that were submitted using a sitemap.xml. Whether you submitted the sitemap.xml to your Google Search Console or not, pages in the sitemap.xml will appear under this label.
Valid: Indexed, not submitted in sitemap
On this list are pages that Google found on its own and decided to index. As I mentioned above, GoogleBot is capable of finding all your public web pages. This list includes pages that it found following your links and that are not part of your sitemap.xml file.
Note that there may be some pages on this list that you do not want to be indexed. For example, your legal pages (disclaimer, privacy policy, terms & conditions, etc.) may not be a great priority for your website. You can mark them with the “NOINDEX” in the robots meta tag:
<meta name="robots" content="NOINDEX"/>
But in most cases, this does not matter much. It’s actually not such a bad thing to have your legal pages indexed because some people may want to search those pages to find something that Google will be capable of matching even with synonyms or even acronyms.